

我们通常把Redis当作一个非本地缓存来运用,很少用到它的一些初级功用。在运用中最容易出成绩的是用Redis来保存JSON数据,由于Redis不像Elasticsearch或许PostgreSQL那样可以很好地支持JSON数据。所以我们常常把JSON当作一个大的String直接放到Redis中,但如今的JSON数据都是连环嵌套的,每次更新时都要先获取整个JSON,然后更改其中一个字段再放上去。
一个常见的JSON数据的Java对象定义如下:
public class Commodity {
private long price;
private String title;
……
}
在海量央求的前提下,在Redis中每次更新一个字段,比如销量字段,都会产生较大的流量。在实践状况下,JSON字符串往往十分复杂,体积到达数百KB都是有能够的,招致在频繁更新数据时使网络I/O跑满,甚至招致系统超时、崩溃。
因此,Redis官方引荐采用哈希来保存对象,比如有3个商品对象,ID辨别是123、124和12345,我们经过哈希把它们保存在Redis中,在更新其中的字段时可以这样做:
HSET commodity:123 price 100
HSET commodity:124 price 101
HSET commodity:12345 price 101
HSET commodity:123 title banana
HSET commodity:124 title apple
HSET commodity:12345 title orange
也就是说,用商品的类型名和ID组成一个Redis哈希对象的KEY。在获取某一属性时只需这样做就可以获取独自的属性:HGET commodity: 12345。
2.Redis的高可用方案:哨兵
Redis官方推出了一个集群管理工具,叫作哨兵(Sentinel),担任在节点中选出主节点,按照散布式集群的管理办法来操作集群节点的上线、下线、监控、提示、自动缺点切换(主备切换),且完成了著名的RAFT选主协议,从而保证了系统选主的分歧性。
这里给出一个哨兵的通用部署方案。哨兵节点普通至少要部署3份,可以和被监控的节点放在一个虚拟机中,常见的哨兵部署如图所示。
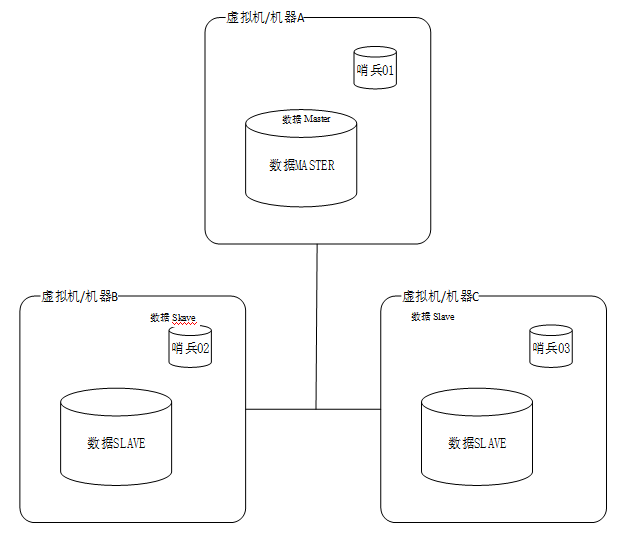
在这个系统中,初始形状下的机器A是主节点,机器B和机器C是从节点。
由于有3个哨兵节点,每个机器运转1个哨兵节点,所以这里设置quorum = 2,也就是在主节点无照应后,有至少两个哨兵无法与主节点通讯,则以为主节点宕机,然后在从节点中选举新的主节点来运用。
在发作网络分区时,若机器A所在的主机网络不可用,则机器B和机器C上的两个Sentinel实例会启动failover并把机器B选举为主节点。
Sentinel集群的特性保证了机器B和机器C上的两个Sentinel实例失掉了关于主节点的最新配置。但机器A上的Sentinel节点依然持有旧的配置,由于它与外界隔离了。
在网络恢复后,我们知道机器A上的Sentinel实例将会更新它的配置。但是,假设客户端所衔接的主机节点也被网络隔离,则客户端将依然可以向机器A的Redis节点写数据,但在网络恢复后,机器A的Redis节点就会变成一个从节点,那么在网络隔离时期,客户端向机器A的Redis节点写入的数据将会丧失,这是不可避免的。
假设把Redis当作缓存来运用,那么我们也许能容忍这部分数据的丧失,但若把Redis当作一个存储系统来运用,就无法容忍这部分数据的丧失了,由于Redis采用的是异步复制,在这样的场景下无法避免数据的丧失。
在这里,我们可以经过以下配置来配置每个Redis实例,使得数据不会丧失:
min-slaves-to-write 1
min-slaves-max-lag 10
经过下面的配置,当一个Redis是主节点时,假设它不能向至少一个从节点写数据(下面的min-slaves-to-write指定了slave的数量),则它将会拒绝接纳客户端的写央求。由于复制是异步的,所以主节点无法向从节点写数据就意味着从节点要么断开了衔接,要么没在指定的时间外向主节点发送同步数据的央求。
所以,采用这样的配置可扫除网络分区后主节点被孤立但依然写入数据,从而招致数据丧失的场景。
3.Redis集群
Redis在3.0中也引入了集群的概念,用于处置一些大数据量和高可用的成绩,但是,为了到达高功用的目的,集群不是强分歧性的,运用的是异步复制,在数据到主节点后,主节点前往成功,数据被异步地复制给从节点。
首先,我们来学习Redis的集群分片机制。Redis运用CRC16(key) mod 16384停止分片,一共分16384个哈希槽,比如若集群有3个节点,则我们按照如下规则分配哈希槽:
A节点包含0-5500的哈希槽;
B节点包含5500-11000的哈希槽;
C节点包含11000-16384的哈希槽。
这里设置了3个主节点和3个从节点,集群分片如图所示。
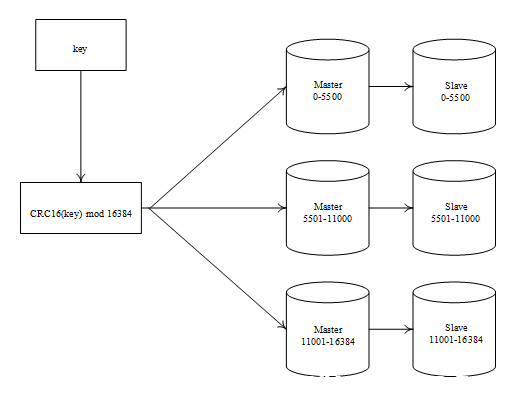
图中共有3个Redis主从效劳器的复制节点,其中恣意两个节点之间都是相互连通的,客户端可以与其中恣意一个节点相衔接,然后拜访集群中的恣意一个节点,对其停止存取和其他操作。
那Redis是怎样做到的呢?首先,在Redis的每个节点上都会存储哈希槽信息,我们可以将它了解为是一个可以存储两个数值的变量,这个变量的取值范围是0-16383。依据这些信息,我们就可以找到每个节点担任的哈希槽,进而找到数据所在的节点。
Redis集群实践上是一个集群管理的插件,当我们提供一个存取的关键字时,就会依据CRC16的算法得出一个结果,然后把结果除以16384求余数,这样每个关键字都会对应一个编号为0-16383的哈希槽,经过这个值找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上停止存取操作。但是这些都是由集群的外部机制完成的,我们不需求手工完成。
作者引见
(责任编辑:admin)