

ММЪѕЩГСњ | 6дТ30ШегыЖрЮЛзЈМвЬжТлММЪѕИпЫйПЊеЙЯТШчКЮгІЖддЫЮЌаТгІеНЃЁ
Python дкДІжУЪ§ОнУдаХвхЮёКЭгІеНЗНУцМЬајДІгкЧРЯШЮЛжУЁЃШЅФъЃЌЮвУЧдјаћВМвЛЦЊВЉПЭЮФеТ Top 15 Python Libraries for Data Science in 2017ЃЌИХЪіСЫЪТЯШвЕвбжЄУїзюгаажњЕФPythonПтЁЃЭљФъЃЌЮвУЧРЉеЙСЫетИіЧхЕЅЃЌЬэМгСЫаТЕФ Python ПтЃЌВЂжиаТЩѓЪгСЫШЅФъдјОЬжТлЙ§ЕФ Python ПтЃЌжиЕуЙизЂСЫетвЛФъРДЕФИќаТЁЃ
ЮвУЧЕФбЁдёЪЕМљЩЯАќКЌСЫ 20 ЖрИіПтЃЌгЩгкЦфжавЛаЉПтЪЧЯрЛЅЬцДњЕФЃЌПЩвдДІжУЯрЗДЕФГЩМЈЁЃвђДЫЃЌЮвУЧНЋЫќУЧЗХдкЭЌвЛИіЗжзщЁЃ
ЈжааФПтКЭЭГМЦЪ§Он
1. NumPy (Commits: 17911, Contributors: 641)
ЙйЭјЃКNumPy ЪЧУдаХдЫгУЫГађПтЕФжївЊШэМўАќжЎвЛЃЌгУгкДІжУДѓаЭЖрЮЌЪ§зщКЭОиеѓЃЌЫќЩйСПЕФГѕМЖЪ§бЇКЏЪ§МЏКЯКЭЭъГЩАьЗЈЪЙЕУетаЉЖдЯѓжДааВйзїГЩЮЊФмЙЛЁЃ
2. SciPy (Commits: 19150, Contributors: 608)
ЙйЭјЃКhttps://scipy.org/scipylib/УдаХМЦЫуЕФСэвЛИіжааФПтЪЧ SciPyЁЃЫќЛљгк NumPyЃЌЦфЙІгУвВвђДЫЪЇЕєСЫРЉеЙЁЃSciPy жїЪ§ОнНсЙЙгжЪЧвЛИіЖрЮЌЪ§зщЃЌгЩ Numpy ЭъГЩЁЃетИіШэМўАќАќКЌСЫажњДІжУЯпадДњЪ§ЁЂИХТЪТлЁЂЛ§ЗжМЦЫуКЭаэЖрЦфЫћвхЮёЕФЙЄОпЁЃДЫЭтЃЌSciPy ЛЙЗтзАСЫаэЖраТЕФ BLAS КЭ LAPACK КЏЪ§ЁЃ
3. Pandas (Commits: 17144, Contributors: 1165)
ЙйЭјЃКhttps://pandas.pydata.org/Pandas ЪЧвЛИі Python ПтЃЌЬсЙЉГѕМЖЕФЪ§ОнНсЙЙКЭИїжжИїбљЕФЦЪЮіЙЄОпЁЃетИіШэМўАќЕФжївЊЬиЕуЪЧПЩвдНЋЯрЕБИДдгЕФЪ§ОнВйзїзЊЛЛЮЊвЛСНИіУќСюЁЃPandasАќКЌаэЖргУгкЗжзщЁЂЙ§ТЫКЭзщКЯЪ§ОнЕФФкжУАьЗЈЃЌвдМАЪБМфађСаЙІгУЁЃ
4. StatsModels (Commits: 10067, Contributors: 153)
ЙйЭјЃКStatsmodels ЪЧвЛИі Python ФЃПщЃЌЫќЮЊЭГМЦЪ§ОнЦЪЮіЬсЙЉСЫаэЖрЪБЛњЃЌР§ШчЭГМЦФЃаЭЙРСПЁЂжДааЭГМЦВтЪдЕШЁЃдкЫќЕФажњЯТЃЌФуПЩвдЭъГЩаэЖрЛњЦїбЇЯААьЗЈВЂЬНЧѓВЛЭЌЕФЛцЭМФмЙЛадЁЃ
Python ПтВЛЖЯПЊеЙЃЌВЛЖЯЗсКёаТЕФЛњгіЁЃвђДЫЃЌЭљФъГіЯжСЫЪБМфађСаЕФИФСМКЭаТЕФМЦЪ§ФЃаЭЃЌМД GeneralizedPoissonЁЂСуЪеЫѕФЃаЭЃЈzero inflated modelsЃЉКЭ NegativeBinomialPЃЌвдМАаТЕФЖрдЊАьЗЈЃКвђзгЦЪЮіЁЂЖрдЊЗНВюЦЪЮівдМАЗНВюЦЪЮіжаЕФжиИДВтСПЁЃ
ЈПЩЪгЛЏ
5. Matplotlib (Commits: 25747, Contributors: 725)
ЙйЭјЃКhttps://matplotlib.org/index.htmlMatplotlib ЪЧвЛИігУгкДДСЂЖўЮЌЭМКЭЭМаЮЕФЕзВуПтЁЃНхгЩЫќЕФажњЃЌФуПЩвдЙЙНЈИїжжВЛЭЌЕФЭМБъЃЌДгжБЗНЭМКЭЩЂЕуЭМЕНЗбЕбПЈЖћзјБъЭМЁЃДЫЭтЃЌгааэЖрЪЂааЕФЛцЭМПтБЛЩшМЦЮЊгыmatplotlibНсКЯдЫгУЁЃ

6. Seaborn (Commits: 2044, Contributors: 83)
ЙйЭјЃКhttps://seaborn.pydata.org/Seaborn БОжЪЩЯЪЧвЛИіЛљгк matplotlib ПтЕФГѕМЖ APIЁЃЫќАќКЌИќЪЪвЫДІжУЭМБэЕФФЌаэЩшжУЁЃДЫЭтЃЌЛЙгаЗсКёЕФПЩЪгЛЏПтЃЌАќРЈвЛаЉИДдгРраЭЃЌШчЪБМфађСаЁЂНсКЯЩЂВМЭМЃЈjointplotsЃЉКЭаЁЬсЧйЭМЃЈviolin diagramsЃЉЁЃ
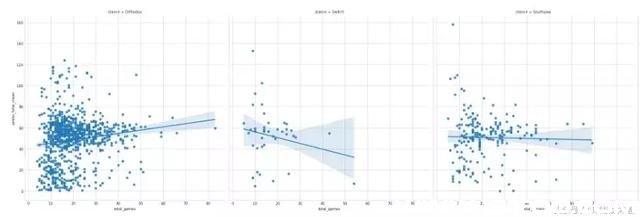
7. Plotly (Commits: 2906, Contributors: 48)
ЙйЭјЃКhttps://plot.ly/python/Plotly ЪЧвЛИіЪЂааЕФПтЃЌЫќПЩвдШУФуЧсЫЩЙЙНЈИДдгЕФЭМаЮЁЃИУШэМўАќЪЪгУгкНЛЛЅЪН Web дЫгУГЬЃЌПЩЭъГЩТжРЊЭМЁЂШ§дЊЭМКЭШ§ЮЌЭМЕШЪгОѕаЇЙћЁЃ
8. Bokeh (Commits: 16983, Contributors: 294)
ЙйЭјЃКhttps://bokeh.pydata.org/en/latest/Bokeh ПтдЫгУ JavaScript аЁВПМўдкдФЖСЦїжаДДСЂНЛЛЅЪНКЭПЩЫѕЗХЕФПЩЪгЛЏЁЃИУПтЬсЙЉСЫЖржжЭМБэМЏКЯЃЌбљЪНФмЙЛадЃЈstyling possibilitiesЃЉЃЌСДНгЭМЁЂЬэМгаЁВПМўКЭЖЈвхЛиЕїЕШЗНЪНЕФНЛЛЅВХФмЃЌвдМАаэЖрИќгагУЕФЬиадЁЃ
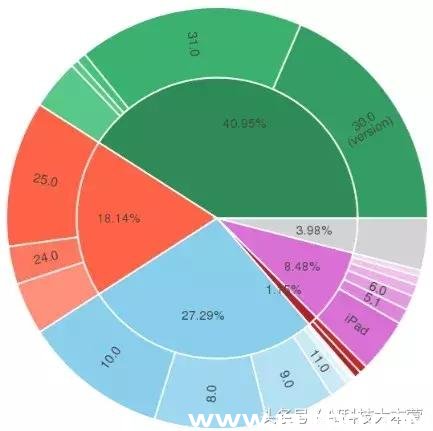
9. Pydot (Commits: 169, Contributors: 12)
ЙйЭјЃКhttps://pypi.org/project/pydot/Pydot ЪЧвЛИігУгкЩњГЩИДдгЕФЖЈЯђЭМКЭЮоЯђЭМЕФПтЁЃЫќЪЧгУДП Python БраДЕФGraphviz НгПкЁЃдкЫќЕФажњЯТЃЌПЩвдЯдЪОЭМаЮЕФНсЙЙЃЌетдкЙЙНЈЩёОЭјТчКЭЛљгкОіВпЪїЕФЫуЗЈЪБГЃГЃгУЕНЁЃ
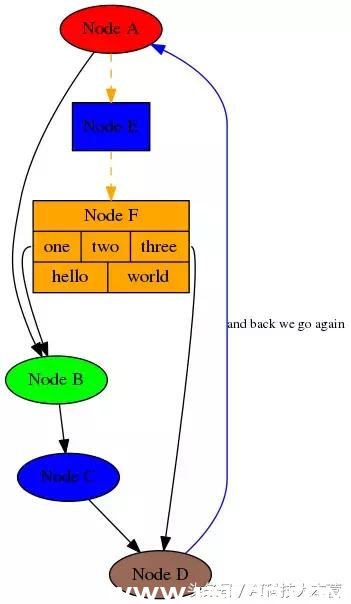
ЈЛњЦїбЇЯА
10. Scikit-learn (Commits: 22753, Contributors: 1084)
ЙйЭјЃКетИіЛљгк NumPy КЭ SciPy ЕФ Python ФЃПщЪЧДІжУЪ§ОнЕФзюМбПтжЎвЛЁЃЫќЮЊаэЖрБъзМЕФЛњЦїбЇЯАКЭЪ§ОнПЊОђвхЮёЬсЙЉЫуЗЈЃЌШчОлРрЁЂЛиЙщЁЂЗжРрЁЂНЕЮЌКЭФЃаЭбЁдёЁЃ
гІгУ Data Science School ЬсИпФуЕФММве
Data Science SchoolЃК11. XGBoost / LightGBM / CatBoost (Commits: 3277 / 1083 / 1509, Contributors: 280 / 79 / 61)
ЙйЭјЃК://lightgbm.readthedocs.io/en/latest/Python-Intro.htmlhttps://github.com/catboost/catboostЬнЖШдіЧПЫуЗЈЪЧзюЪЂааЕФЛњЦїбЇЯАЫуЗЈжЎвЛЃЌЫќЪЧЪїСЂвЛИіВЛЖЯИФСМЕФЛљБОФЃаЭЃЌМДОіВпЪїЁЃвђДЫЃЌЮЊСЫПьЫйЁЂЗНБуЕиЭъГЩетИіАьЗЈЖјЩшМЦСЫзЈУХПтЁЃОЭЪЧЫЕЃЌЮвУЧвдЮЊ XGBoostЁЂLightGBM КЭ CatBoost жЕЕУЬиБ№ЙизЂЁЃЫќУЧЖМЪЧДІжУГЃМћГЩМЈЕФОКељепЃЌВЂЧвдЫгУЗНЪНМђжБЯрЗДЁЃетаЉПтЬсЙЉСЫИпЖШгХЛЏЕФЁЂПЩРЉеЙЕФЁЂПьЫйЕФЬнЖШдіЧПЭъГЩЃЌетЪЙЕУЫќУЧдкЪ§ОнУдаХМвКЭ Kaggle ОКељЖдЪжжаЪЎЗжЪЂааЃЌгЩгкдкетаЉЫуЗЈЕФажњЯТВЉЕУСЫаэЖрБШШќЁЃ
12. Eli5 (Commits: 922, Contributors: 6)
ЙйЭјЃКhttps://eli5.readthedocs.io/en/latest/ЭЈГЃзДПіЯТЃЌЛњЦїбЇЯАФЃаЭдЄВтЕФНсЙћВЂВЛЭъШЋЧхГўЃЌете§ЪЧ Eli5 ажњгІЖдЕФгІеНЁЃЫќЪЧвЛИігУгкПЩЪгЛЏКЭЕїЪдЛњЦїбЇЯАФЃаЭВЂж№НЅИњзйЫуЗЈШЮЮёЕФШэМўАќЃЌЮЊ scikit-learnЁЂXGBoostЁЂLightGBMЁЂlightning КЭ sklearn-crfsuite ПтЬсЙЉжЇГжЃЌВЂЮЊУПИіПтжДааВЛЭЌЕФвхЮёЁЃ
ЈЩюЖШбЇЯА
13. TensorFlow (Commits: 33339, Contributors: 1469)
ЙйЭјЃКhttps://www.tensorflow.org/ (д№ШЮБрМЃКadmin)МзЙЧЮФЙШИшАцШЈжЎеНЃЌФузюГЃгУЕФШэМўЛђаэБЛ
ЮЂШэЗЂВМ Visual Studio ПЊеЙТЗЭОЭМЃЌЩйСП
ПЦММаавЕаНГъзюИпЕФ15жжжАЮЛ ПДПДФудкФФвЛ
StackOverflow ЕїВщЃКИЛгаЙњЖШЪЂаа Python
WebAssembly дйЬэвЛдБУЭНЋЃКНЋжЇГждЫгУ Go
JavaАИЫфвбГОАЃТфЖЈЃЌЕЋШэМўНчЕФСЌЫјЗДЯьВХ
Git 12ЫъСЫЃЌЮЊФуЫЭЩЯ12ИіGit ЕФдЫгУММЧЩЃЁ
дњПЫВЎИё13ФъЧАаДЕФFacebookЭјеОДњТыЃЌФуМћ
