

改良的调度和缺点恢复:最后,Blink 完成了对义务调度和容错的若干改良。调度策略经过应用操作符处置输入数据的方式来更好地运用资源。缺点转移策略沿着耐久 shuffle 的边界停止更细粒度的恢复。不需重新启动正在运转的运用顺序就可以交流发作缺点的 JobManager。
Blink 的变化带来了大幅度的功用提升。以下数据由 Blink 开发者提供,给出了功用提升的粗略状况。
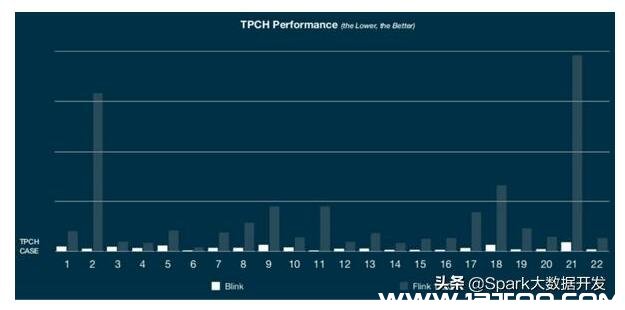
在 TPC-H 基准测试中,Blink 与 Flink 1.6.0 的相对功用。Blink 功用平均提升 10 倍
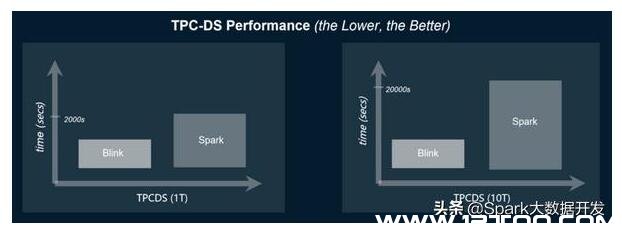
在 TPC-DS 基准测试中,Blink 与 Spark 的功用,将一切查询的总时间汇总在一同。
Blink 和 Flink 的兼并方案
Blink 的代码目前曾经作为 Flink 代码库的一个分支(https://github.com/apache/flink/tree/blink )对外开放。兼并这么多变更是一项艰难的应战,同时还要尽能够保持兼并进程不要形成任何中缀,并使公共 API 尽能够保持波动。
社区的兼并方案最后将重点放在上述的有界 / 批处置功用上,并遵照以下办法以确保可以顺利集成:
为了兼并 Blink 的 SQL/Table API 查询处置器增强功用,我们应用了 Flink 和 Blink 都具有相反 API 的理想:SQL 和 Table API。在对 Table/SQL 模块( https://cwiki.apache.org/confluence/display/FLINK/FLIP-32%3A+Restructure+flink-table+for+future+contributions )停止一些重组之后,我们方案将 Blink 查询规划器(优化器)和运转时(操作符)兼并为以后 SQL 运转时的附加查询处置器。可以将其视为同一 API 的两个不同的运转器。最末尾,可以让用户选择要运用哪个查询处置器。经过一个过渡期之后,将开发新的查询处置器,而以后的处置器很能够会被弃用,并最终被丢弃。由于 SQL 是一个定义良好的接口,我们估量这种转换对用户来说简直没有影响。
为了兼并 Blink 的调度增强功用和有界数据的作业恢复功用,Flink 社区曾经在努力重构以后的调度功用,并添加对可插拔调度和缺点转移策略的支持。在完成这项任务后,我们就可以将 Blink 的调度和恢复策略作为新查询处置器的调度策略。最后,我们方案将新的调度策略运用于有界 DataStream 顺序。
扩展的目录支持、DDL 支持以及对 Hive 目录和集成的支持目前正在停止独自的设计讨论。
总 结
我们置信未来的数据处置技术栈会以流式处置为基础:流式处置的优雅,可以以相反的方式对离线处置(批处置)、实时数据处置和事情驱动的运用顺序停止建模,同时还能提供高功用和分歧性,这些真实是太吸引人了。成都加米谷大数据培训,大数据开发,数据剖析与开掘,小班教学,收费试听。
要让流式处置器完成与公用批处置器相反的功用,应用有界数据的某些属性是关键。Flink 支持批处置,但它的下一步是要构建一致的运转时,并成为一个可以与批处置系统相竞争的流式处置器。阿里巴巴贡献的 Blink 有助于 Flink 社区加快完成这一目的。
英文原文:https://flink.apache.org/news/2019/02/13/unified-batch-streaming-blink.html
【编辑引荐】
开发者其实不太需求关注 Java 收不收费
Uber 宣布开源 AI 工具箱,免代码训练和测试学习模型
转战、停服、跑路,昌盛DApp生态背后的开发者
法国迷信家开收回能像蚂蚁一样导航的六足机器人
AI研讨机构OpenAI开收回写作AI:编写假旧事足以乱真
(责任编辑:admin)